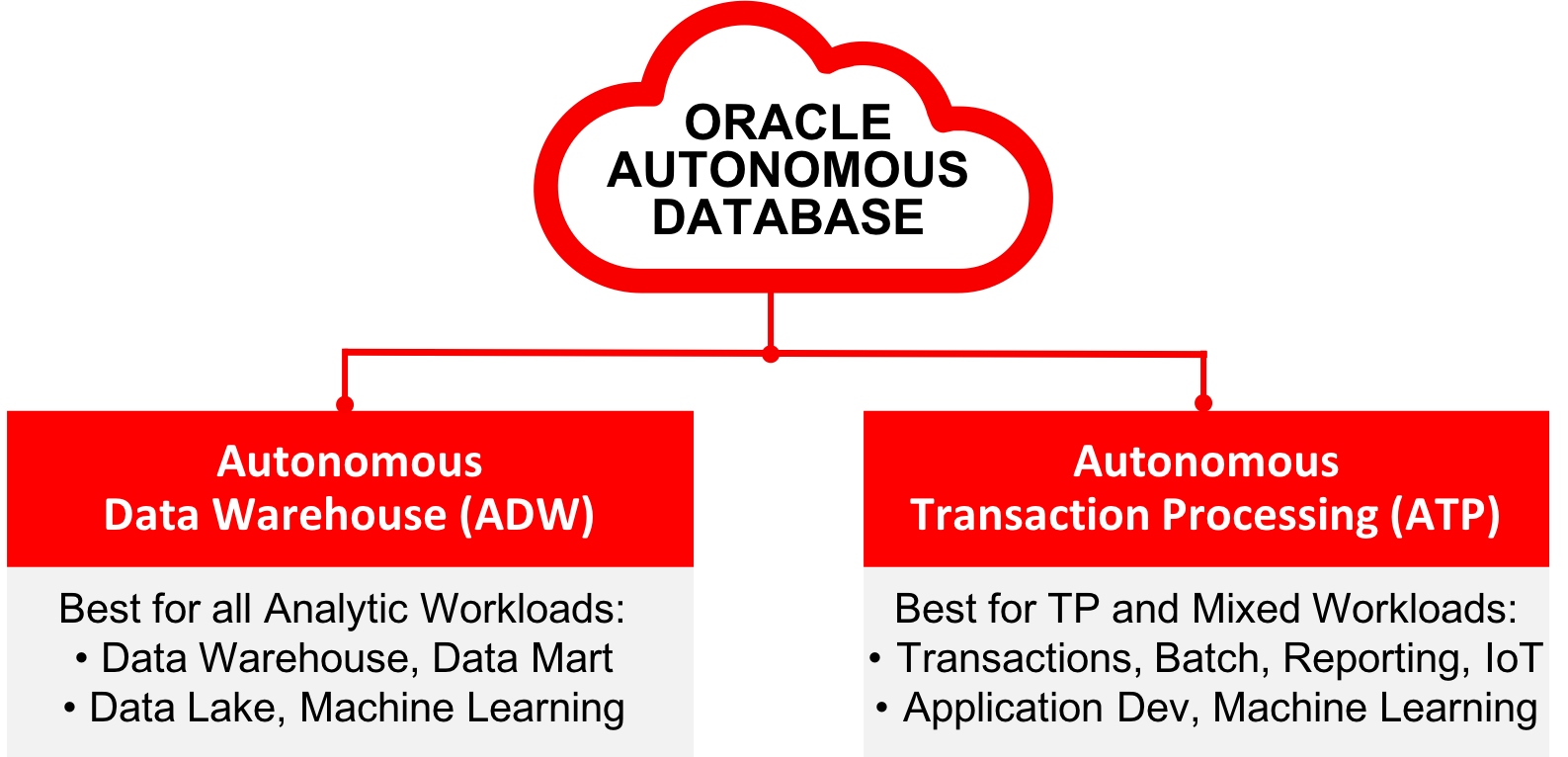
ATP is a self-driving database that is built to run a complex mix of high-performance database, along with other workloads like IoT, reporting, batch jobs, Real-time analytics, and Machine learning. ATP is built on the same autonomous database as Autonomous Data warehouse (ADW). So, the benefits of ADW apply to ATP as well. ATP is designed to execute a high volume of simple transactions efficiently.
Oracle Autonomous Transaction Processing DB Services on Azure, GCP, AWS, OCI

Trusted by Global Enterprises
0+Years Experience
0+Unique Customers
0+Solutions Delivered
ISO 27001Certified
SOC 2Type II Compliant
Why ATP?
- 1Low Cost ATP reduces cost by providing automation through Machine learning. It runs on Exadata hardware to deliver much better performance.
- 2Reduced Risk Data is always available, secure and protected. The security updates have been automated and guarantee 99.95 % of availability. The SLA can be further increased to 99.995% by deploying active data guard across regions.
- 3Accelerated Innovation Provisioning and maintenance of database is completely automated. The application developers can now deploy their applications quickly by instantiating the autonomous database in minutes.
- 4Data formats In ATP, data is stored in a row format. The row format is ideal for transaction processing as it allows quick access and updates to all of the columns in an individual record since all of the data for a given record is stored together in-memory and on-storage.
- 5Statistics Gathering With ATP, data is added using more traditional insert statements. Statistics are automatically gathered when the volume of data changes significantly enough to make a difference to the statistics.
- 6Resource Gathering In ATP only one service (PARALLEL) automatically runs SQL statements with parallel execution. ATP uses the medium priority service by default which allows the low priority service allocated for requests such as reporting and batch jobs. This feature prevents these low priority tasks from interfering with mainstream transaction processing.
Loading...
Schedule Meeting